The Database and its Open-Source Dependencies
Building a database from scratch is often considered daunting. However, the Rust programming language and its open-source community have made it easier.
With a team of three experienced developers, we have implemented ScopeDB from scratch to production in four months, with the help of Rust and its open-source ecosystem.
ScopeDB is a shared-disk architecture database in the cloud that manages observability data in petabytes. A simple calculation shows that we implemented such a database with about 50,000 lines of Rust code, with 100 direct dependencies and 647 dependencies in total.
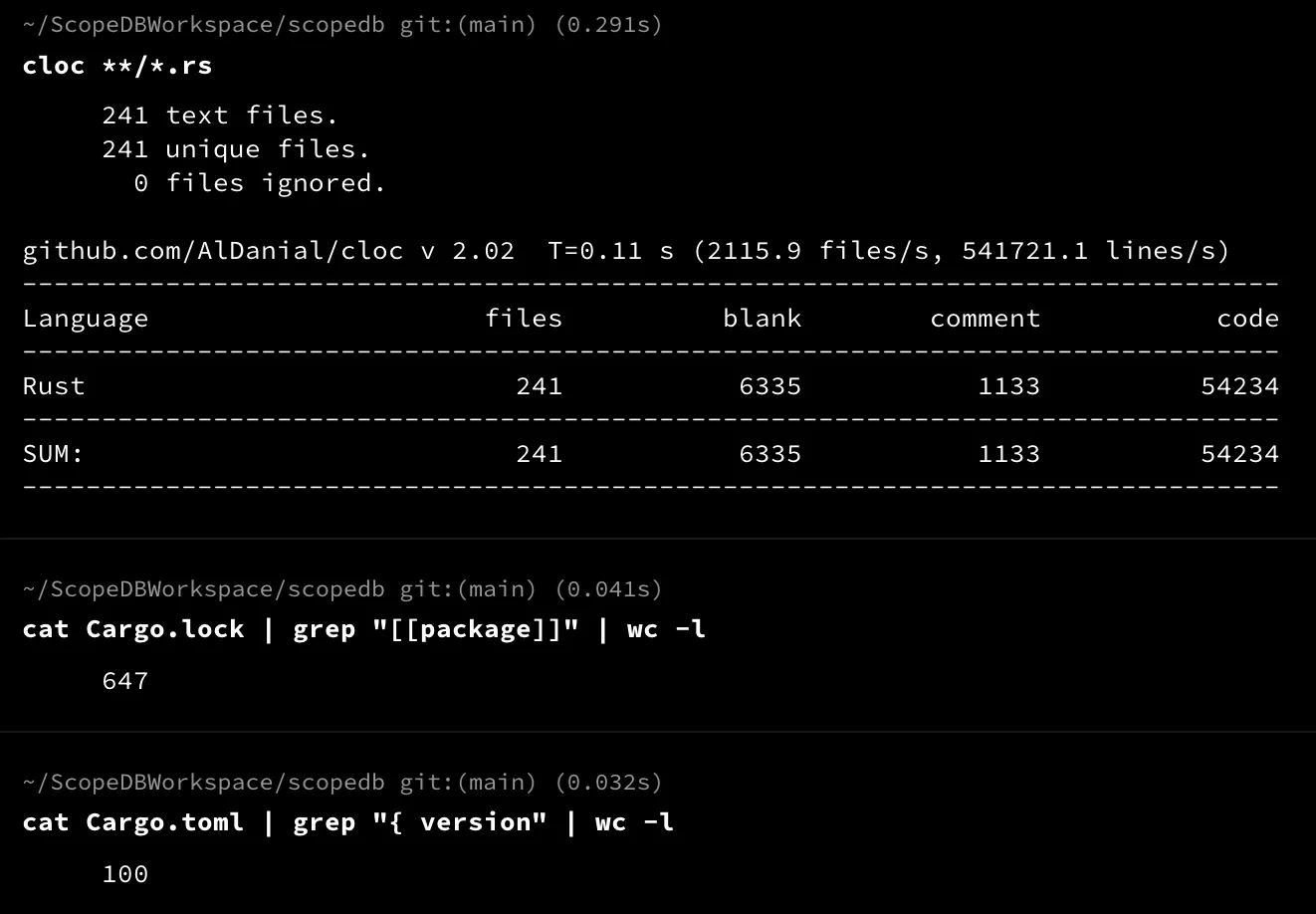
Here are several open-source projects that we have heavily used to build ScopeDB:
- ScopeDB stores user data in object storage services. We leverage Apache OpenDAL as a unified interface to access various object storage services at users’ choice.
- ScopeDB manages metadata with relational database services. We leverage SQLx and SeaQuery to interact efficiently and ergonomically with relational databases.
- ScopeDB supports multiple data types. We leverage Jiff with its
TimestampandSignedDurationtypes for in-memory calculations, and ordered-float to extend the floating point numbers with total ordering.
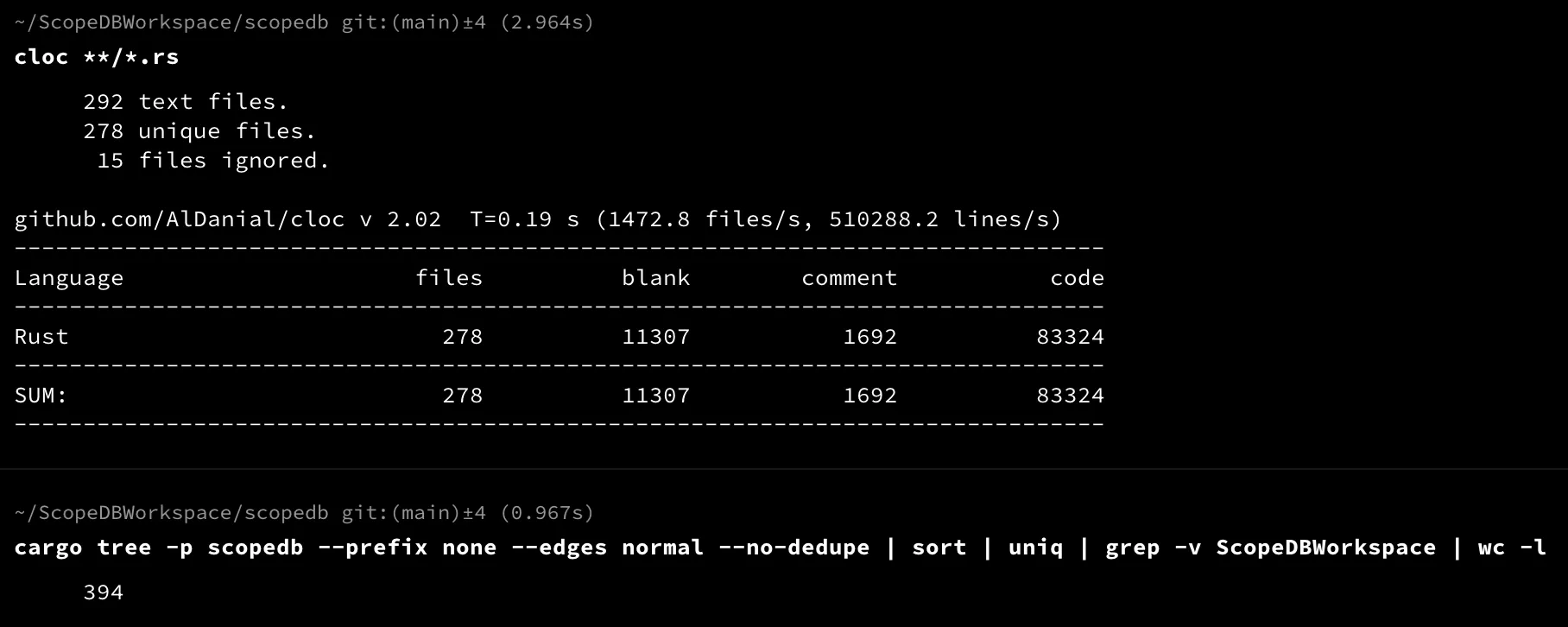
UPDATE (2025-01-15): Filtered internal crates, the open-source dependencies are 623 in total. Check out this Gist to see if your project is one of them :D (Note that a dependency in the lockfile may not be used in the final binary)
UPDATE (2025-02-17): After review the dependencies and remove unnecessary ones, the ScopeDB binary now depends on 394 open-source crates in total, with all the dependencies vet and many of them are managed by our team members.
Besides, during the development of ScopeDB, we spawned a few common libraries and made them open-source. We have developed a message queue demo system as its open-source twin.
In the following sections, I will discuss how we got involved and contributed to the upstreams and describe the open-source projects we developed.
Involve and Contribute Back to the Upstreams
Generally speaking, when you start to use an open-source project in your software, you will always encounter bugs, missing features, or performance issues. This is the most direct motivation to contribute back to the upstreams.
For example, during the migration from pull-based metric reporting to push-based metric reporting in ScopeDB, we implemented a new layer for OpenDAL to support report metrics via opentelemetry:
When onboarding our customers to ScopeDB, we developed a tool to benchmark object storage services with OpenDAL’s APIs. We contributed the tool back to the OpenDAL project:
To integrate with the data types provided by Jiff and ordered-float, we often need to extend those types. We try our best to contribute those extensions back to the upstreams:
- feat: optionally integrate with num-cmp
- feat: integrate with derive-visitor
- feat: implement Hash trait for structs that has implemented PartialEq
We leverage Apache Arrow for its Array abstraction to convey data in vector form. We have contributed a few patches to the Arrow project:
- Support cast between Durations + between Durations all numeric types
- feat: add write_bytes for GenericBinaryBuilder
Even if the extension can be too specific to ScopeDB, we share the code so that people who have the same needs can use the patch:
I’m maintaining many open-source projects, too. Thus, I understand the importance of user feedback even if you don’t encounter any issues. A simple “thank you” can be an excellent motivation for the maintainers:
- Feedback to upgrade jiff to 0.1.16
- Showcase how I use this crate to crate a mapping between (secured) business object and serializable dto
Sometimes, except for the code, I also contribute to the documentation or share use cases when a certain feature is not well-documented:
- sqlx::Type for Enum with String repr
- docs: base url relative join
- How to construct array of list of list and array of list of struct?
- RustlsConfig to be reloadable
- Type for an Acceptor that maybe TLS or not
- Transform errors when extract parameters
Many times, contributing back is not one-directional. Instead, it’s about communication and collaboration.
We used to leverage testcontainers-rs for behavior testing, but later, we found reusing containers across tests necessary. We fall back to using Ballord to implement the reuse logic. We shared the experience with the testcontainers-rs project:
So far, a contributor has shown up and implemented the feature. I helped test the feature with our open-source twin, which I’ll introduce in the following section.
By the way, as an early adopter of Jiff, we shared a few real-world use cases, which Jiff’s maintainer adjusted the library to fit:
Usually, after the integration has been done, there are fewer opportunities to collaborate with the upstream unless new requirements arise or our core functions cover the upstream’s main evolution direction. In the latter case, we will become an influencer or maintainer of the upstream.
Inside Out: The Database’s Open-Source Components
In addition to using open-source software out of the box, during the development of ScopeDB, we also write code to implement some common requirements, because there is no existing open-source software that satisfies our requirements directly. In this case, we will actively consider open-sourcing the code we wrote.
Here are a few examples of the open-source projects we developed during the development of ScopeDB:
Fastrace originated from a tracing library made by our team members during the development of TiKV. After several twists and turns, this library was separated from the TiKV organization and became one of the cornerstones of ScopeDB’s own observability. Currently, we are actively maintaining the Fastrace library.
Logforth originated from the need for logging when developing ScopeDB. We initially used another library to complete this function. Still, we soon found that the library had some redundant designs and had not been maintained for over a year. Therefore, we quickly implemented a logging library that meets the needs of ScopeDB and can be easily extended, and open sourced it.
To support scheduled tasks within the database system, we developed Fastimer to schedule different tasks in different manners. And to allow database users to define scheduled tasks with CREATE JOB statement, we developed Cronexpr to support users specify the schedule frequency using cron expressions.
Last but not least, ScopeDB’s SDK is open-source. Obviously, there is no benefit in privating the SDK, since the SDK does not have commercial value by itself, but is used to support ScopeDB’s user development applications. This is the same as Snowflake keeps its SDKs open-source. And when you think about it, GitHub also has its server code private and proprietary, while keeping its SDKs, CLIs, and even action runners open-source.
An Open-Source Twin and the Commercial Open-Source Paradigm
Finally, to share the engineering experience in implementing complex distributed systems using Rust, we developed a message queue system that roughly has the same architecture as ScopeDB’s:
As mentioned above, when verifying the container reuse function of testcontainers-rs, our ultimate goal is to use it in the ScopeDB project. However, ScopeDB is a private software, and we cannot directly share upstream developers with ScopeDB’s source code for testing. Instead, Morax, as an open-source twin, can provide developers with an open-source reproduction environment:
I have presented this commercial open-source paradigm in a few conferences and meetups:

When you read The Cathedral & the Bazaar, for its Chapter 4, The Magic Cauldron, it writes:
… the only rational reasons you might want them to be closed is if you want to sell the package to other people, or deny its use to competitors. [“Reasons for Closing Source”]
Open source makes it rather difficult to capture direct sale value from software. [“Why Sale Value is Problematic”]
While the article focuses on when open-source is a good choice, these sentences imply that it’s reasonable to keep your commercial software private and proprietary.
We follow it and run a business to sustain the engineering effort. We keep ScopeDB private and proprietary, while we actively get involved and contribute back to the open-source dependencies, open source common libraries when it’s suitable, and maintain the open-source twin to share the engineering experience.
Future Works
If you try out the ScopeDB playground, you will see that the database is still in its early stages. We are experiencing challenges in improving performance in multiple ways and supporting more features. Primarily, we are actively working on accelerating async scheduling and supporting variant data more efficiently.
Besides, we are working to provide an online service to allow users to try out the database for free without setting up the playground and unleash the real power of ScopeDB with real cloud resources.
If you’re interested in the project, please feel free to drop me an email.
I’ll keep sharing our engineering experience developing Rust software and stories we collaborate with the open-source community. Stay tuned!